
簡単なデータ分析であれば「スプレッドシート」や「エクセル」を利用して行うことが多いのですが、大量で多種多様なデータを分析するには「スプレッドシート」や「エクセル」では役者不足感です。いかんせ処理が重いし、設定が面倒すぎます。
気軽にビックデータをクロス集計する場合はPandasのpivot_table()やcrosstab()をよく使用しています。これを知っているか知らないかでは生産性が雲泥の差なのでお薦めです。
今回はpivot_table()関数について紹介させていただきます。
また、集計関数の指定の仕方についてはこちらにて紹介させていただいています。
準備
まずはテストデータの準備です。
データの読み込み
テストデータはこの業界でお馴染みのタイタニックデータとなります。
import pandas as pd
# タイタニックデータの取得
url='https://raw.githubusercontent.com/mwaskom/seaborn-data/master/raw/titanic.csv'
titanic=pd.read_csv(url)
# データの確認
titanic.head(3)| a | survived | pclass | name | sex | age | sibsp | parch | ticket | fare |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | Braund, Mr. | male | 22.0 | 1 | 0 | A/5 | 7.25 |
| 1 | 1 | 1 | Cumings, | female | 38.0 | 1 | 0 | PC | 17599 |
| 2 | 1 | 3 | Heikkinen, | female | 26.0 | 0 | 0 | STO | 7.9250 |
欠損データの補填
素のタイタニックデータだとage(年齢)項目に欠損(NaN)があるため、欠損レコードが無効となってしまいます。
それに対応するため、NaNの部分には年齢の平均値で穴埋めします。
# 年齢に欠損があるので欠損値に平均年齢を代入
titanic["age"] = titanic["age"].fillna(titanic["age"].median())
クロス集計
まずはシンプルなクロス集計を紹介します。
基本的な集計
こちらは、pclass(客室クラス)を行、sex(性別)を列に指定して、age(年齢)の平均値を集計します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age')このように客室クラスx性別の平均年齢が表示されました。
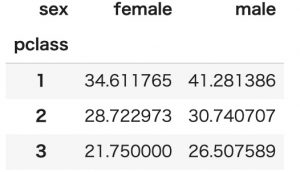
やっぱり男性も女性も高級クラス(1)に泊まるのは高年齢層で、下級クラス(3)は若者なんですね。
あと気になったのが、女性の方が若いんですね。高年齢の女性は旅をしないのかな?
小計と総計データの追加
次は客室クラスx性別の平均年齢に小計と総計を算出します。
具体的にはpivot_tableのパラメータにmargins=Trueを追加すれば算出されます。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', margins=True)先の結果にAll行とAll列が追加されて、小計と総計が算出されました。
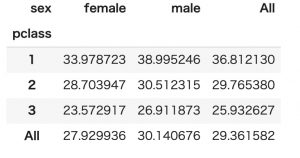
やっぱり、女性の平均が27.9歳、男性平均が30.1歳なので男性の方が高年齢ですね。亭主の移動に奥様が付き添っている感じなんでしょうね。
あと勝手な想像ですが、高級クラスは年配の夫婦が使用していると思われるので、当時の夫婦の年齢差は5歳ぐらいなんでしょうね。多分ですが。
件数のクロス集計
今度は平均年齢ではなく件数で集計してみたいと思います。
件数集計する場合はaggfunc パラメータにlenを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', margins=True, aggfunc=len高級客室に宿泊している女性は94人で、男性は122人という感じです。
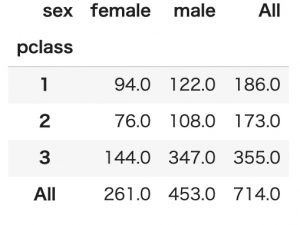
件数の正規化集計
これまでのクロス集計だと値の平均値を集計するだけで他レコードとの比較がしにくい状態です。
例えばある項目が100だったとして、その100が大きいのか小さいのかがわかりません。
他の項目が10だったら大きいだろうし、200とか300だったら小さいだろうしでなかなか判断がつきましせん。
そのため、行や列ごとに合計を1で正規化して大小比較ができるようにします。
行で正規化
列で正規化する例です。
aggfuncでlambda指定ができるのですが、引数が指定できないので一旦オブジェクト化してapply()で再定義します。
こちらの例は行の合計が1となるので行のデータの比較が容易になります。
tmp=pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=len)
tmp.apply(lambda x : x/sum(x),axis=1)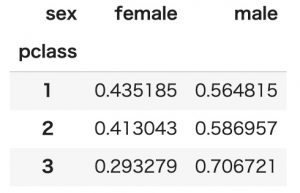
列で正規化
こちらの例は列の正規化となります。
列のデータの合計値が1となるため、列データでの比較をする際に便利です。
tmp=pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=len)
tmp.apply(lambda x : x/sum(x),axis=0)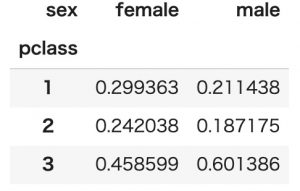
集計の指定の仕方についてはこちらをご確認ください。


コメント