
前回は基本的なpivot_table()関数の使い方を説明いたしましたが、今回は集計の計算方法の指定について紹介したいと思います。
pivot_table()関数はデフォルトでmean(平均値)を使って算出しますが、aggfuncパラメータで指定することにより集計方法を任意のものに指定できます。
集計の種類
今回、紹介するのは以下の集計となります
| 集計 | 関数 |
|---|---|
| 件数 | len |
| 合計 | np.sum |
| 最小値 | np.min |
| 最大値 | np.max |
| 中央値 | np.median |
| 平均値 | np.mean |
| 標準偏差 | np.std |
サンプルデータの取得
前回に引き続きタイタニックデータを例に説明いたします
import numpy as np
import pandas as pd
# タイタニックデータの取得
url='https://raw.githubusercontent.com/mwaskom/seaborn-data/master/raw/titanic.csv'
titanic=pd.read_csv(url)
# 年齢に欠損があるので欠損値に平均年齢を代入
titanic["age"] = titanic["age"].fillna(titanic["age"].median())
# データの確認
titanic.head(3)| a | survived | pclass | name | sex | age | sibsp | parch | ticket | fare |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | Braund, Mr. | male | 22.0 | 1 | 0 | A/5 | 7.25 |
| 1 | 1 | 1 | Cumings, | female | 38.0 | 1 | 0 | PC | 17599 |
| 2 | 1 | 3 | Heikkinen, | female | 26.0 | 0 | 0 | STO | 7.9250 |
客室ランク(pclass)と性別(sex)を掛け合わせた年齢(age)の集計を例といたします
件数、合計
件数
件数を算出するには組み込み関数のlen()を指定します。
ただし、関数を指定する場合は()をつけないように気をつけてください。
単純に件数を求めるのであればcrosstab()関数の方がオススメです。こちらの方が正規化(Normalize)指定が選択できるため、分布を測定するにはcrosstab()関数を使うことが多いです。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=len)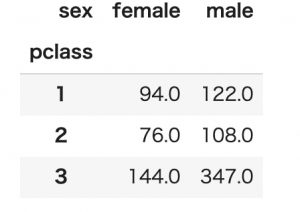
合計
values値の合計値を見るにはnp.sumを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.sum)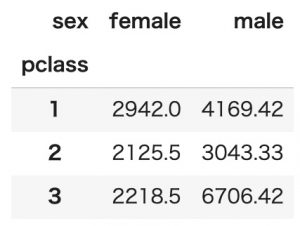
最大/最小/中央値
最大値
values値の最大値を見るにはnp.maxを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.max)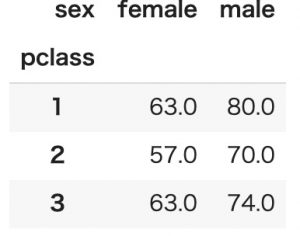
最小値
values値の最小値を見るにはnp.minを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.min)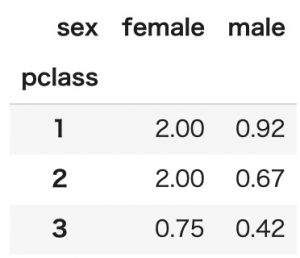
中央値
values値の中央値を見るにはnp.medianを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.median)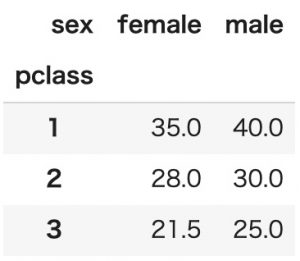
平均値、標準偏差
平均値
values値の平均値を見るにはnp.meanを指定します。
aggfuncはnp.meanがデフォルト値なので平均値を取得したい場合はaggfuncを指定しないことの方が多いです。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.mean)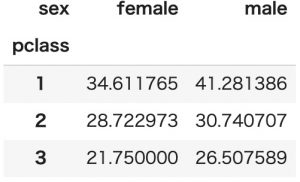
標準偏差
values値の標準偏差を見るにはnp.stdを指定します。
pd.pivot_table(titanic, index='pclass', columns='sex', values='age', aggfunc=np.std)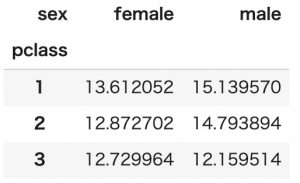


コメント