
RDS→lambda→CSV→S3 Export処理の概要
AWSで構築されたDBデータ(RDS)をGCPのデータ分析環境へ定期的にエクスポートするための手順を纏めました。
分析環境がAWSであればAWSGlueやDataPiplineで良かったのですが、GCPを想定しているため、これらでは襷に長し帯に短しであったため見送りました。無駄に学習コストが高くてオーバースペックでした。
フロートしては以下のような感じです
- lambdaの起動
- mysqldumpをS3よりダウンロード
- mysqldumpを実行してdumpファイルを取得
- dumpファイルをCSVデータへ変換
- CSVファイルをS3へアップロード
AWSサービスと言語の構成
- AWSサービス
- lambda
- RDS(AuroraMySQL)
- S3
- 言語
- python3.7
- SQL
- ツール
- mysqldump
AWSの設定手順
S3バケットの作成
まずはCSVファイルの格納先であるS3バケットを作成します。
また、mysqldumpのバイナリーデータも格納する必要があるためそれ用のディレクトリも用意しましょう。
例:
バケット名:nishiken-test
ディレクトリ名:bin/
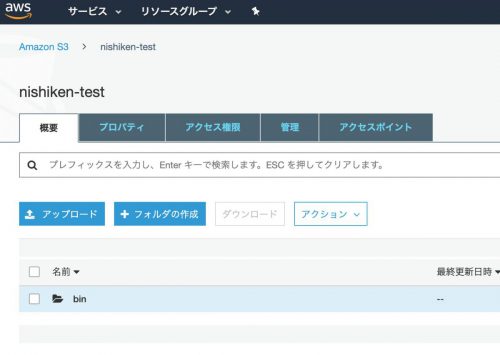
mysqldumpを取得
適当な開発環境よりmysqldumpのバイナリーファイルを取得します。
もし開発環境がないようであれば適当なEC2のインスタンスを立ててmysqlクライアントをインストールします。もしMacを利用しているのであればMacでも可能です。
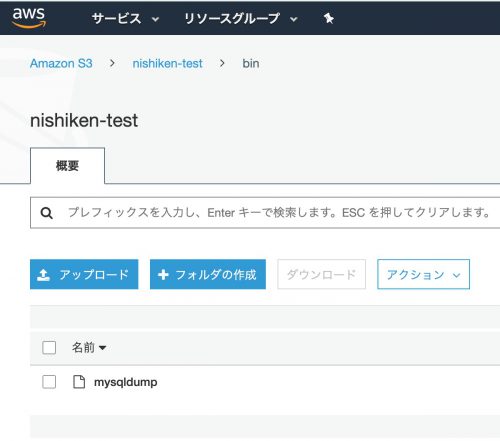
lambdaではローカル環境にバイナリーを格納するという概念がないため、取得したmysqldumpファイルをS3環境へ保存する必要があります。
実行例:
# yumを利用してインストール
$ sudo yum install mysql-community-client
# mysqldumpの格納場所を検索
$ which mysqldump
/usr/local/bin/mysqldump
# S3へmysqldumpファイルをコピー
aws s3 cp /usr/local/bin/mysqldump s3://nishiken-test/bin/.S3コンソールで確認:
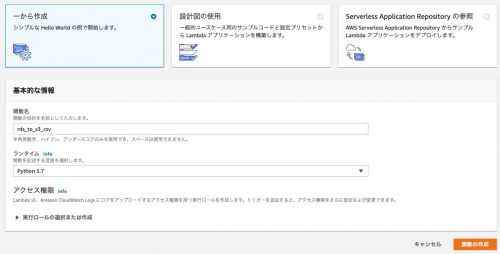
lambda関数の作成
lambda関数を作成します。
設定例:
関数名:rds_to_s3_csv
ランタイム:Python3.7
こんな感じな画面になるので、ここでCSVエクスポートのPythonコードを記入します。
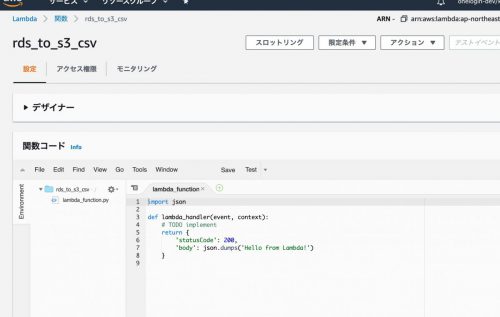
Pythonのコーディング
関数コードのエリアに以下を記入
import subprocess
import pprint
import boto3
import os
import re
# S3情報
S3_BUCKET_NAME='nishiken-test'
S3_MYSQLDUMP_BIN='bin/mysqldump'
MYSQLDUMP_BIN='/tmp/mysqldump'
# RDS接続情報
RDS_HOST='ip_to_rds'
RDS_ID='rds_id'
RDS_PW='rds_pw'
# ExportDB情報
DATA_DB='export_db'
DATA_TBL='export_table'
def lambda_handler(event,context):
"""RDSデータのCSVファイル書き出し処理(S3へ)
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
try:
# s3クライアントの取得
s3=boto3.client('s3')
# S3よりmysqldumpファイルを取得
s3.download_file( S3_BUCKET_NAME, S3_MYSQLDUMP_BIN, MYSQLDUMP_BIN )
ret=os.path.isfile(MYSQLDUMP_BIN)
if ret is False:
pprint.pprint(ret)
raise Exception(f'mysqldump取得処理エラー:{ret.stderr}')
# mysqldumpに実行権限を付与
ret=subprocess.run( f'chmod +x {MYSQLDUMP_BIN}', shell=True, stderr=subprocess.PIPE )
if ret.returncode!=0:
pprint.pprint(ret.stderr)
raise Exception(f'mysqldump権限付与エラー:{ret.stderr}')
# mysqldumpコマンドの作成
dump_file=f'{DATA_DB}-{DATA_TBL}.sql'
cmd=f'{MYSQLDUMP_BIN} -u{RDS_ID} -p{RDS_PW} -h{RDS_HOST} -t --single-transaction --skip-opt --compact {DATA_DB} {DATA_TBL}>/tmp/{dump_file}'
# mysqldumpの実行
ret=subprocess.run(cmd,shell=True,stderr=subprocess.PIPE)
if ret.returncode!=0:
pprint.pprint(ret.stderr)
raise Exception(f'mysqldump実行エラー: cmd:{cmd} msg:{ret.stderr}')
# DUMPファイルを取得してCSVデータに変換
with open(f'/tmp/{dump_file}', mode='r') as f:
csv=f.read()
# 強引に置換
csv=re.sub(r'INSERT INTO `.+` VALUES \(', '', csv)
csv=re.sub(r'\);\n','\n',csv)
# S3へ保存
csv_file=f'{DATA_DB}-{DATA_TBL}.csv'
s3.put_object(Bucket=S3_BUCKET_NAME, Key=csv_file, Body=csv)
# DUMPファイルの削除
ret=subprocess.run(f'rm -fr /tmp/{dump_file}',shell=True,stderr=subprocess.PIPE)
if ret.returncode!=0:
pprint.pprint(ret.stderr)
raise Exception(f'ダンプファイル削除エラー: dump_file:{dump_file} msg:{ret.stderr}')
# 正常終了
return 0
except Exception as e:
# エラー処理
pprint.pprint(e)
return 9テスト実行と運用について
動作検証は画面右上にある「テスト」ボタンを押下すれば実行可能です。
GCPのCloudFunctionsに比べてデプロイの時間が短いためlambdaの開発はサクサク進みますね。
実行でエラーになる場合はロールの設定とVPC周りを見直してみて下さい。ここらへんは各環境ごとに異なるため千差万別になります。
定期的にスケジュール実行したい場合はCloudWatch Eventに登録すれば、cronのようなスケジュール指定が可能となります。
最後に
AWSまわりは不勉強でわからないことだらけでしたが、なんとかlambdaが使えるようになりました。サーバーレスのコード実行環境は便利ですね。データ分析の幅も広がる手応えを感じました。
Pythonのコードですが重要情報をソースにベタ書きしていますが、本当は環境変数やconfファイルに設定するようにして下さい


コメント