
データ分析をするにはまずデータの取得が必要となります。
だいたいは以下のデータソースが基本となるため、GoogleColaboratoryでこれらからの入出力するための手法についてまとめました。
- インターネット
- CSVファイル
- スプレッドシート
その他にもGCSや各種DBなどがありますが、それらは随時追記していきたいと思います。
八割方はPandasさんが対応してくれて超有能です。
その他にもBigQueryやSalesForceデータやS3ファイルなどもありますが、これらはボリューム的にまとめて紹介はできないため、別記事として取り上げたいと思います。
BigQueryについてはこちらにまとめました
準備
Gドライブとのマウント
ColaboratoryではデフォルトでGドライブとの連携がされていませんので、まずはじめにGドライブへマウントをする必要があります。
#ドライブ設定
PATH_GMOUNT='/content/gdrive'
PATH_MYDRIVE=PATH_GMOUNT+'/My Drive'
#GDriveマウント
from google.colab import drive
drive.mount(PATH_GMOUNT)を実行するとGドライブとの接続認証へのリンクが表示されるため、画面遷移でアクセスリクエストの許可を行い、ログインコードをコピーして、もとのColaboratoryページにてログインコードを入力してください。
Mounted at /content/gdriveのメッセージが表示されれば無事にマウント完了です。
ネットよりCSVファイルを取得
ネットより直接csvデータを取得する方法です。
埼玉県和光市のオープンデータ【和光市】年齢・男女別住民基本台帳人口をURL指定で取得する例です。
pandasのread_csv()関数一発でCSVファイルを取得して、Pandasのデータフレームに格納してくれます。
import pandas as pd
# 【和光市】年齢・男女別住民基本台帳人口
URL_CSV='https://opendata.pref.saitama.lg.jp/data/dataset/2067c2d8-8da2-4e4b-ad51-730408369c7b/resource/6355cb31-b460-4a72-9ab8-3ecb8a6b2085/download/h31.3.31.csv'
df = pd.read_csv(URL_CSV,encoding="SHIFT-JIS",header=2)
#最後に余計な行があるので削除
df=df.drop(df.index[len(df)-1])
df.head(3)和光市のデータはSHIFT-JIS形式だったのでencoding指定をしないとエラーとなります。また、CSVのレイアウトが2行目まで余計なタイトルなどがあったためheader指定をして取得する必要があります。
結果以下のようなデータを取得できました。
| 年齢 | 総数 | 男 | 女 | |
|---|---|---|---|---|
| 0 | 総数 | 82,876 | 42,649 | 40,227 |
| 1 | 0 | 798 | 392 | 406 |
| 2 | 1 | 814 | 414 | 400 |
Gドライブファイル
CSVファイル出力
PandasデータフレームをCSVファイルに保存するのはto_csv()関数でOKです。
Gドライブのパス指定に作法はありますが、わかっていれば大した問題ではありません。
パラメータindexにFalseを設定しています。これを指定しないとindexの連番が出力されてしまうため、それを防ぎます。
PATH_MYDRIVE=PATH_GMOUNT+'/My Drive'
df.to_csv(f'{PATH_MYDRIVE}/wakoushi.csv', index=False)
!ls -lrt '{PATH_MYDRIVE}'!から始まるシステムコマンド「!ls -lrt」で作成されたCSVファイルを確認しました。
出力はUTF-8でファイル作成されます。
-rw------- 1 root root 2004 Mar 16 14:22 wakoushi.csvCSVファイルの読み込み
CSVファイルの読み込みはさらに簡単です。
はじめに使用したread_csv()関数のパラメータをGドライブのCSVファイル名に変更するだけです。
df = pd.read_csv(f'{PATH_MYDRIVE}/wakoushi.csv')
df.head(3)当然結果はこうなります。
| 年齢 | 総数 | 男 | 女 | |
|---|---|---|---|---|
| 0 | 総数 | 82,876 | 42,649 | 40,227 |
| 1 | 0 | 798 | 392 | 406 |
| 2 | 1 | 814 | 414 | 400 |
スプレッドシート
スプレッドシートの操作はgspreadというライブラリーを使用します。
こちらを参考にしました。
APIリファレンス
諸々のサンプル
準備
スプレッドシートを操作するライブラリーをインストールする必要があります。
以下の外部コマンドを実行していただければほんの数秒でインストール作業が終了します。
# スプシの読み込みのパッケージ取得
!pip install --upgrade -q gspreadスプレッドシートの認証をした後にスプレットシートクライアントを取得します。
from google.colab import auth
from oauth2client.client import GoogleCredentials
import gspread
# アクセス認証
auth.authenticate_user()
# スプシクライアントの取得
gc = gspread.authorize(GoogleCredentials.get_application_default())Gドライブの接続認証と同様の処理が行えればOKです。
スプレッドシートへの書き出し
データフレームに格納された和光市のデータをスプレッドシートに書き出します。
処理の流れとしては以下の通りです。
- スプレッドシートの作成
- ワークシートの作成
- データフレームの書き出し
# スプシをマイドライブに新規作成
sh=gc.create('【和光市】年齢・男女別住民基本台帳人口')
# シートを取得
worksheet=sh.get_worksheet(0)
#データフレームの内容をLISTに変換して書き出す
worksheet.update([df.columns.values.tolist()]+df.values.tolist())書き込みが完了すれば、マイドライブに「【和光市】年齢・男女別住民基本台帳人口」というスプレッドシートが新規作成されて、以下のようなシートが作成されています。
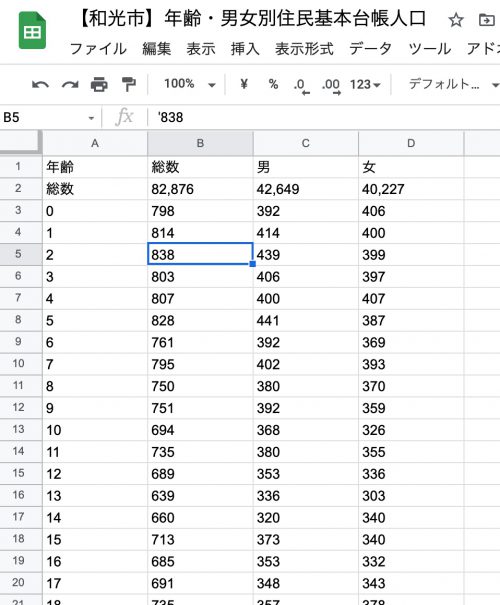
スプレッドシートからの読み込み
シートからデータを取得するにはワークシートオブジェクトのget_all_records()を利用します。
取り急ぎ今回の例では先程インスタンス化したworkseetオブジェクトを利用した例となります。
URLからシートオブジェクトを作成する例は後ほど記述します。
# シートから全データを辞書型データとして読み込む
new_dic=worksheet.get_all_records(head=1)
# 辞書型データをデータフレームに格納する
new_df=pd.DataFrame(new_dic)
new_df.head(3)当然結果はこうなります。
| 年齢 | 総数 | 男 | 女 | |
|---|---|---|---|---|
| 0 | 総数 | 82,876 | 42,649 | 40,227 |
| 1 | 0 | 798 | 392 | 406 |
| 2 | 1 | 814 | 414 | 400 |
こちらがURLからシートオブジェクト取得してワークシートを指定する例となります。
# スプレッドシートのURLを定義
SHEET_URL='---GoogleスプレッドシートのURL---'
# スプレッドシートオブジェクトの取得
sh= gc.open_by_key(SPREADSHEET_KEY)
# ワークシートオブジェクトの取得
worksheet= sh.worksheet('sheet1')

コメント